Image

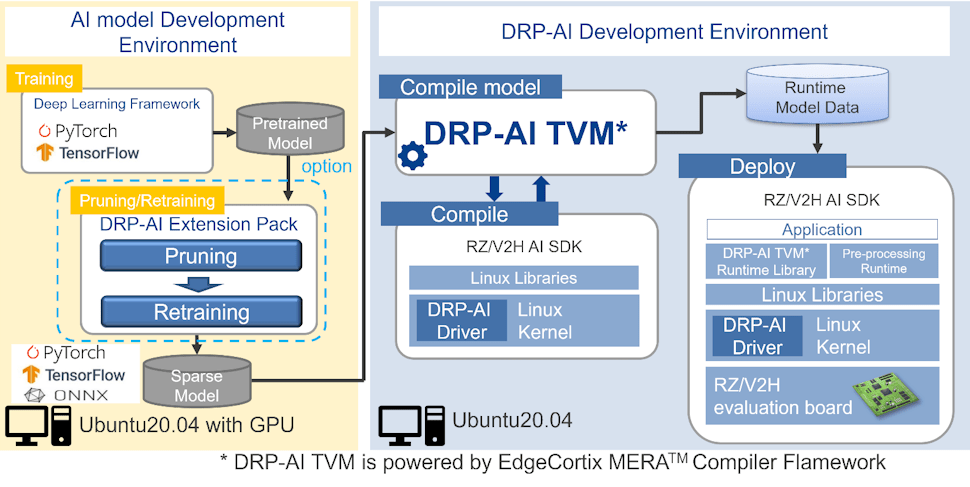
DRP-AI for RZ/V2H supports a feature for efficiently calculating the pruned AI model. The DRP-AI Extension Pack provides a pruning function optimized for RZ/V2H. The DRP-AI optimized pruning function can be used in combination with this tool and PyTorch or TensorFlow training code.
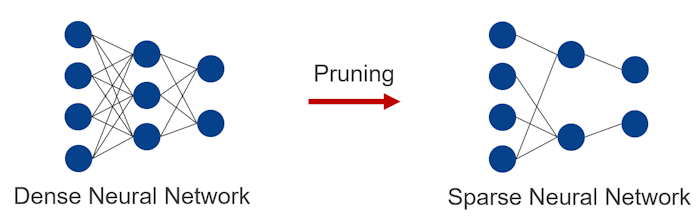
Nodes in a neural network are interconnected as shown in the figure. Methods of reducing the number of parameters by removing weights between nodes or removing nodes are referred to as “pruning”. A neural network to which pruning has not been applied is generally referred to as a dense neural network. And a neural network to which pruning has been applied is generally referred to as a sparse neural network. Applying pruning leads to a slight deterioration in the accuracy of the model but can reduce the power required by hardware and accelerate the inference process.
The pruned model can be embedded using DRP-AI TVM. Refer to the DRP-AI TVM page on GitHub for details on TVM.
https://github.com/renesas-rz/rzv_drp-ai_tvm
Note: As shown in the figure, pruning is an optional function. (Dense model also can be embedded.)
The RZ/V2H AI MPU evaluation kit (RTK0EF0168C04000BJ) is used to evaluate Renesas' RZ/V2H quad-core vision AI MPU. The kit includes a CPU board and an expansion (EXP)...
